
Yolov5_训练and识别
环境配置
python 3.8.5
安装conda
1 | wget -c https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh |
如果还有没有安装上的请继续安装。
github源
主要参考的是官方yolov5.
https://github.com/ultralytics/yolov5
训练自己的任务
训练前的配置
主要采用COCO数据集,配置好上述的环境后,就可以进行使用。
首先更改你的dataset.yaml文件
1 | # Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..] |
自己的数据按照上述的路径进行修改。
打标签
图像和标签分别放在 labels和images两个目录下,可以通过makesense.ai打标签,但更推荐开源标签软件-LabelImg。
将标签导出为YOLO 格式,.txt每个图像一个文件(如果图像中没有对象,则不需要.txt文件)。该*.txt文件规格有:
- 每个对象一行
- 每一行都是class x_center y_center width height格式。
- 框坐标必须采用标准化 xywh格式(从 0 - 1)。如果您的箱子以像素为单位,划分x_center并width通过图像宽度,y_center并height通过图像高度。
- 类号是零索引的(从 0 开始)。

如图所示,分别代表了分类0的矩形的x\y宽高。
数据集整理
将自己的数据集按照以上的方式进行一个整理,然后进行学习训练。
例如:
1 | 数据集/iamges/im0.jpg #图像 |
选择一个预训练模型
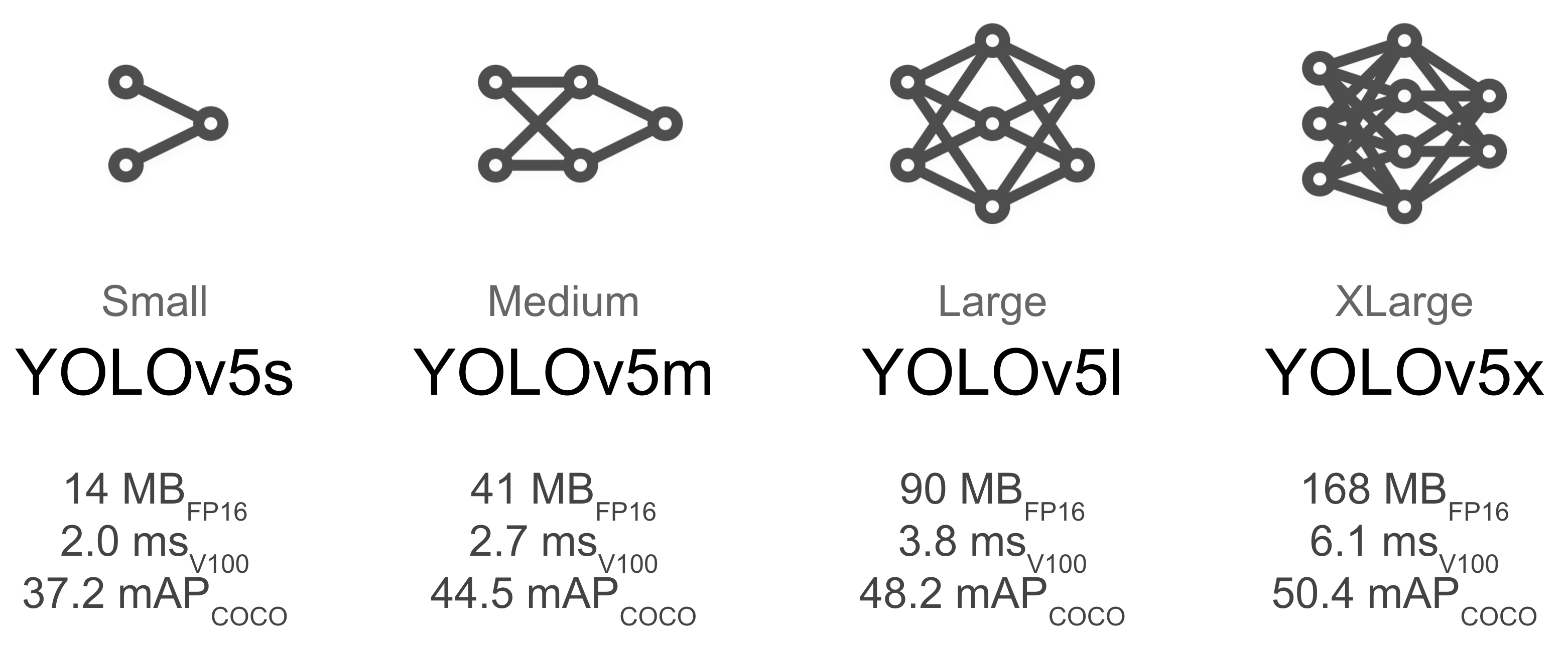
选择一个预训练模型开始训练。这里我们选择YOLOv5s,这是可用的最小和最快的模型。
进行训练
YOLOv5s 5 epochs $ python train.py --img 640 --batch 16 --epochs 5 --data dataset.yaml --weights yolov5s.pt
训练结果


目标检测
运行程序进行识别(将识别模型改成自己的进行使用)
1 | $ python detect.py --source 0 # webcam |
训练coco模型可以
1 | $ python train.py --data coco.yaml --cfg yolov5s.yaml --weights '' --batch-size 64 |
树莓派安装Berryconda+pytorch
安装conda
Berryconda
不建议安装Miniconda的armv7l二进制包,它的包都很久没有更新了。直接使用Berryconda,armv7l版本可以在rpi4上正常使用,下载并安装:
1 | wget https://github.com/jjhelmus/berryconda/releases/download/v2.0.0/Berryconda3-2.0.0-Linux-armv7l.sh |
miniconda
1 | uname -a |
创建虚拟环境
conda create -n pytorch python=3.8
pytorch
安装依赖
source activate pytorch
sudo apt-get install libopenblas-dev m4 libblas-dev cmake
conda install opencv numpy pyyaml cython
pip install numpy==1.16
1 | git clone https://github.com/pytorch/pytorch.git |



- 本文链接:http://www.codekp.cn/2021/07/19/yolo5%E4%BD%BF%E7%94%A8/
- 版权声明:本博客所有文章除特别声明外,均默认采用 许可协议。
您可以点击下方按钮切换对应评论系统。
GitHub Issues